
Redis KEYS: 성능 저하의 원인
Redis는 빠른 데이터 접근를 목적으로 설계된 메모리 기반 데이터 저장소입니다.
Redis에서 여러 커맨드가 존재하는데, 그 중에서 KEYS 명령어는 특정 패턴에 매칭되는 모든 키를 검색하는 기능을 제공합니다.
실무 환경에서 이를 사용하는 것은 권장하지 않습니다.
이번 포스팅에서는 KEYS 명령어를 왜 사용하면 안되며 대체할 커맨드를 소개하겠습니다.😊
KEYS 명령어의 기능 및 동작 원리
KEYS 명령어란?
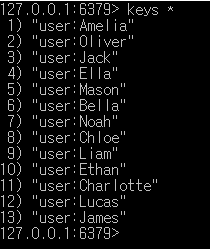
KEYS <pattern> 명령어는 지정된 패턴과 일치하는 모든 키를 검색해 반환합니다.
테스트나 디버깅 단계에서 유리할 수 있지만 프로덕션 환경 즉, 서비스 중인 어플리케이션에서는 심각한 문제가 발생할 수 있습니다.
동작 방식
Redis는 내부적으로 모든 키를 단일 글로벌 네임스페이스에 저장합니다. KEYS 명령어를 실행하면,
저장된 모든 키를 순차적으로 검사하여 패턴과 일치하는 키를 찾습니다.
KEYS 명령어가 위험한 이유
O(n) 시간 복잡도
KEYS 명령어는 저장된 키의 수에 비례한 O(n)의 시간 복잡도를 가집니다.
저장된 키가 많을수록 수행 시간이 기하급수적으로 늘어납니다.
- 1,000,000개의 ‘user:’ 키가 저장된 상태에서
KEYS user:*를 실행하면 Redis는 100만개의 키를 하나씩 검사합니다. - 결과적으로 서버의 성능 저하와 CPU 사용률이 급증합니다.
싱글 스레드 구조와 블로킹 이슈
Redis는 싱글 스레드로 명령어를 처리하므로 명령어들의 실행속도는 빠릅니다.
KEYS 명령어처럼 모든 데이터를 탐색해야 하는 작업은 Redis의 효율성을 저하시킵니다.
KEYS명령어는 싱글 스레드 상에서 동기적으로 실행됩니다.- 데이터 양이 많을 수록 탐색 작업이 완료될 때까지 다른 명령어 요청을 처리하지 못합니다.
- 작업 중 Redis가 다른 명령어 요청을 처리하지 못하는 블로킹 동작이 발생합니다.
KEYS를 안전하고 빠르게 사용하기 위해서 데이터를 저장할 때 적절한 키를 사용해야 할까요?
어떤 상황에서든 KEYS를 사용하는 경우 위와 같은 위험은 피해갈 수 없습니다.
위 상황을 회피하기 위해 소개할 명령어는 SCAN입니다.
SCAN은 데이터를 한꺼번에 반환하지 않고 호출을 반복적으로 나누어 처리하므로 다른 명령어 요청을 병렬로 처리할 수 있게 합니다.
SCAN 명령어 (KEYS 대안)
SCAN은 KEYS 명령어와 유사한 기능을 제공하지만, non-blocking 방식으로 동작합니다.
작은 배치 단위로 데이터를 반환하므로 프로덕션 환경에서 안전하게 사용할 수 있습니다.
사용법
SCAN cursor [MATCH pattern] [COUNT count]
- cursor: 현재 스캔 위치를 나타내는 숫자입니다.
처음 시작할 때는 0으로 설정하고 반환된 새로운 cursor 값을 통해 다음 스캔을 이어갈 수 있습니다. - MATCH pattern: 옵션으로 특정 패턴에 맞는 키만 스캔합니다.
- COUNT count: 옵션으로 한 번에 반환할 키의 개수를 지정합니다.
반드시 정확한 개수를 반환하지 않으며 Redis 내부의 상황에 따라 반환되는 개수가 달라질 수 있습니다.
예시
SCAN 0 MATCH user:* COUNT 5
cursor = 0에서 시작하여 user:로 시작하는 키들을 검색하고 5개의 키를 반환하려고 시도합니다.
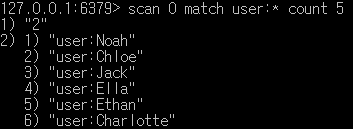
- 첫 번째 항목의 “2”는
SCAN명령어가 반환된 새로운 커서 값입니다.
이 커서 값으로 다음SCAN명령어를 시작해야 합니다. - 두 번째 항목은
user:*패턴과 일치하는 키들의 리스트입니다.
Redis는 내부적인 상황에 따라 요청한 개수보다 더 많은 키를 반환할 수 있기 때문에 이 경우에는 6개의 키가 반환되었습니다.
결과
KEYS 명령어는 쉽게 사용할 수 있지만 성능 문제와 서비스 안정성에 부정적인 영향을 줄 수 있습니다.
프로덕션 환경에서는 SCAN 명령어를 사용하고 키 네임스페이스 설계와 자료구조 활용 방식을 개선하는 것을 추천합니다.